This article proposes a possible target environment on Databricks using the Unity Catalog.
Installation and configuration of the target environment are not part of biGENIUS support.
Unfortunately, we won't be able to provide any help beyond this example in this article.
Many other configurations and installations are possible for a Databricks target environment.
Below is a possible target environment setup for the Databricks Stage Files generator using the Unity catalog.
The Unity Catalog Property must be set to true:
![]()
Setup environment
The Databricks target environment needs at least the following Azure resources set in your Azure Subscription:
- A Ressource Group: some help is available here
- Inside the Ressource Group:
In the following example of the target environment, we will use the following resources:
- A Ressource Group named bg-databricks
- A Storage Account for our Source Data named bgdatabrickslandingzone1
- A Storage Account for our Target Data Lake named bgdatabricksdatalake1
- An Azure Databricks Service named bgaas-unity
- An Access Connector for Azure Databricks named bgaasunity

Tools to install
Please install the following tools:
- Azure Storage Explorer: available here
Source Storage Account
Please upload the source Parquet files to the Source Storage Account:
- Open Azure Storage Explorer
- Connect to your Subscription
- Open the Source Storage Account
- Create one folder by Parquet Source file
The folder name should be identical to the Parquet file name.
For this example, we have 2 Parquet source files, so we need 2 folders:
 Upload in each folder the corresponding Parquet Source file, for example, for the SalesOrderDetail folder:
Upload in each folder the corresponding Parquet Source file, for example, for the SalesOrderDetail folder:

We have the following Delta File containing Credit Card data in our target storage account named bgdatabrickslandingzone1:

Target Storage Account
We have chosen to create a folder named bronze in our Target Storage Account:
- Open Azure Storage Explorer
- Connect to your Subscription
- Open the Target Storage Account
- Create a folder
For this example, we have 1 Target folder for our Data Lake:
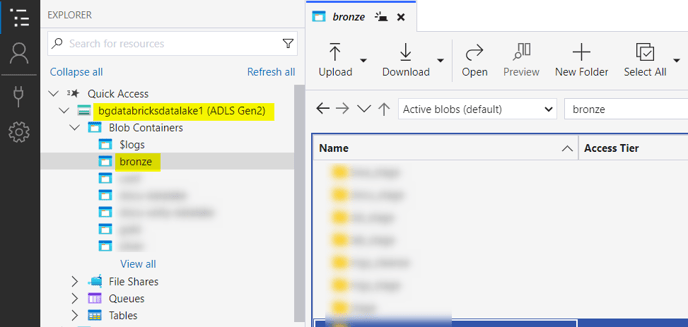
Unity Catalog
We must prepare the database and schemas in our Unity catalog.
For this example, we created:
- A database named datalakehouse
- A schema named docu_stage
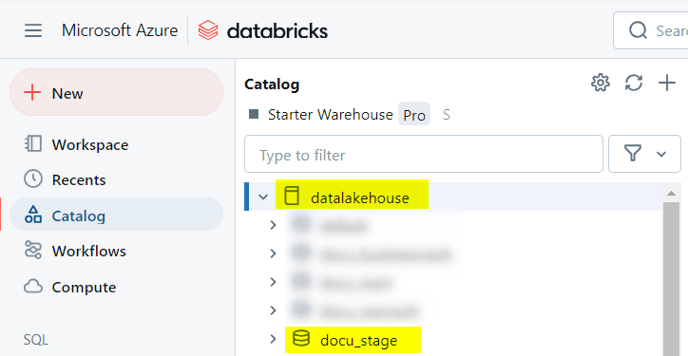
Upload Artifacts in Databricks
Please now upload the generated Artifacts from the biGENIUS-X application to the Databricks Workspace.
Please replace the placeholders before uploading the artifacts.
- Click on the Azure Databricks Service in Azure:

- Then click on the URL:

- Databricks is opened:

- Click on the Workspace menu on the left-hand-side:

- Expand the folders Workspace > Users and click on your user:

- We have chosen to create a folder named artifacts_files_stage:

- Import all the generated artifacts from the folder Jupyter, Helpers, and LoadControl:

It is possible to have one or several files not imported as:

It is due to Databricks itself.
Just restart the import for the concerned files, and it should work.
- Import, in addition, the following helper:
In the file 500_Deploy_and_Load_DataVault_Databricks.ipynb, adapt the name of the XXX_Deployment.ipynb, the XXX_SimpleLoadexecution.ipynb, the XXX_MultithreadingLoadExecution.ipynb, and the XXX_SelectResults.ipynb by the name of your Helper files.
Create a Personal Compute
To be able to execute the Notebooks from our generated artifacts, please create a Personal Compute in Databricks:
- Click on the Compute menu on the left-hand-side:

- Click on the Create with Personal Compute button:

- Change the following information:
- Databricks runtime version: choose "13.3 LTS (Scala 2.12, Spark 3.4.1)
- Click on the Create compute button:

- Wait until the Personal Compute is available:

If you have already discovered your source data, modeled your project, and generated the artifacts, you're now ready to replace the placeholders in your generated artifacts, deploy these artifacts, and subsequently load the data based on the Generator you are using with the following possible load controls: