There are three different options to define the architecture of a BI solution:
- The Data Vault modeling (Dan Linstedt)
- The Dimensional modeling (Star Schema / Ralph Kimball)
- The Relational approach (Header and Version)
The choice is up to you: Each type of modeling has benefits and drawbacks that depend on your project's specific needs (the number of sources, the update frequency of your sources, etc.).
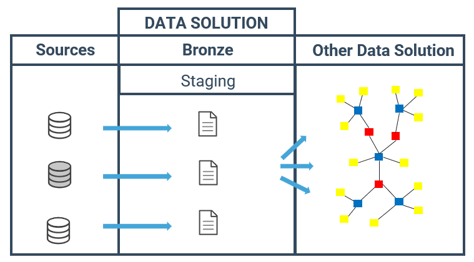
You can also use specific architectures (Stage, Stage File, Stage JDBC, Stage OpenQuery, Data Store, Data Mart) to split your Data Solution into smaller pieces.
Data Vault Modeling
Invented by Dan Linstedt in the 1990s, the Data Vault modeling is a scalable Data Solution architecture.
Data Vault should store "all data, any time." Data should not be cleansed.

From the source data, the Data Vault Data Solution is composed of 3 layers:
- Bronze: Staging
- Silver: Raw Data Vault and Business Data Vault
- Gold: Marts
Then you can base your reporting on the Gold layer.
The Data Solution is based on the source data (the source system or an ODS based on the source system) and transforms the data in a Data Vault modeling (Hubs, Links, Satellites in the Silver Layer Group).
- The business transformations are done in the Silver Layer Group only
- Complete historization of all attributes
- Can be multi-sourced
- Ability to scale the model
You can base your Data Vault project on an ODS, such as the Dimensional or Relational approach, and construct a Data Mart on your Data Vault Modeling.
Please look at Model a Data Vault Solution for more details.
Dimensional Modeling
Over the past 20 years, Ralph Kimball's approach has proven effective for reporting. It optimizes data for user queries. It is also referred to as Star Schema.

From the source data, the Dimensional Data Solution is composed of 3 layers:
- Bronze: Staging
- Silver: Cleansing and Core
- Gold: Marts
Then you can base your reporting on the Gold layer.
This architecture can contain the following Project types:
The Data Solution is based on the source data (the source system or an ODS based on the source system) and transforms the data into a snowflake schema (core: facts and entities) and a star schema (mart: fact tables and dimensions).
- The business transformations are done in the Silver Layer Group only.
- If a source system is replaced over time, the old and the new source system / ODS will be maintained as the source.
- It can be multi-sourced.
- In biGENIUS-X, the Data Solution can be split into multiple projects for different purposes, for example
- to minimize the effort by doing a biGENIUS project for standard dimensions (Date, Customer, Geography, etc.)
- to keep a domain utterly separate from the rest (i.e., HR reporting)
Please look at Model a Dimensional Solution for more details.
Relational Modeling
Soon available in biGENIUS-X!
The relational Data Solution approach differs from the star schema / Kimball approach in the following aspects:
- It is a snowflake schema
- The modeling is done in the third normal form
- The design uses primarily entities and only rarely facts
- Master data entities are split up into two tables:
- Header table: Contains the business key and all SCD0 and SCD1 attributes
- Version table (optional): Contains all SCD2 attributes. Historization is done in the CORE layer in the version tables of an entity.
- Transactional data can be modeled as entities or facts depending on the loading requirements (Merge or Insert only or different fact load strategies)

From the source data, the Relational Data Solution is composed of 3 layers:
- Bronze: Staging
- Silver: Cleansing and Core
- Gold: Marts
Then you can base your reporting on the Gold layer.
The Data Solution is based on the source data (source system or ODS based on the source system) and transforms the data into a relational schema.
Specific architectures
Stage
The Stage Modeling can be used to load data from a source database to spli your Data Solution into smaller pieces and to reuse the Stage Solution in different other Data Solutions.

From the source data, the Stage Solution is composed of 1 layer:
- Bronze: Staging
Then you can base your other Data Solutions on it.
Please look at Model a Stage Solution for more details.
Stage JDBC
The Stage JDBC Modeling can be used to load data from a JDBC source to target files.
From the source data, the Stage Solution is composed of 1 layer:
- Bronze: Staging
Then you can base your other Data Solutions on it.
Please look at Model a Stage JDBC Solution for more details.
Stage File
The Stage File Modeling can be used to load data from a source files to target files or databases.

From the source data, the Stage Solution is composed of 1 layer:
- Bronze: Staging
Then you can base your other Data Solutions on it.
Please look at Model a Stage File Solution for more details.
Stage OpenQuery
The Stage OpenQuery Modeling can be used to load data from a source accessible through an OpenQuery to a database.

From the source data, the Stage Solution is composed of 1 layer:
- Bronze: Staging
Then you can base your other Data Solutions on it.
Please look at Model a Stage OpenQuery Solution for more details.
Data Store
The needed data is stored for each source; no data transformation is done. The Data Solution is then based on the operational data stores.
Advantages of having a Data Store:
- The ODS is loaded once per load frequency. The Data Solution will access the ODS and not the source systems, so there are no performance problems.
- The ODS can be historized (technical tracking of the changes in the source) if the source does not provide data historization. It enables a more straightforward Data Solution modeling, avoiding historization in the Data Solution.
- The ODS can monitor source deletions.
- Recreating the Data Solution is possible anytime as the ODS has all the data.
An ODS may be unnecessary if a Data Hub or an equivalent exists.
Please look at Model a Data Store Solution for more details.
Data Mart
A data mart is a structure/access pattern specific to data solution environments that retrieves client-facing data. The data mart is a data solution subset usually oriented to a particular line of business or team.
In biGENIUS, you can model one Data Mart project by business topic using the system configuration Data Mart. This is done in the Gold layer.
Please look at Model a Data Mart Solution for more details.